
With organizations becoming more reliant than ever before on data availability, a new array of terms describing different types of redundancies has entered the IT infrastructure lexicon. In many cases, these terms don’t quite mean what they sound like or create a misleading impression about what specific circumstances they actually cover.
Sometimes, similar-sounding terms may be used interchangeably despite referring to very different concepts. A good example of this latter problem is two terms related to redundancy: fault tolerance vs high availability.
While they both describe methods of delivering high levels of SLA uptime, they achieve those levels in very different ways. To avoid confusion, it’s worth taking the time to understand how they relate to network and data center redundancies, server downtime, and how they differ from one another.
What is a Fault Tolerant System?
In simple terms, fault-tolerant computing is a form of full hardware redundancy. Two (or more) systems operate in tandem, mirroring identical applications and executing instructions in lockstep with one another.
When a hardware failure occurs in the primary system, the secondary system running an identical application simultaneously takes over with no loss of service and zero downtime. This approach could be used to prevent a data center outage, for example, by ensuring that all mission-critical hardware is fully backed up by identical systems.
Fault-tolerant computing requires specialized hardware that can immediately detect faults in components and keep the mirrored systems running in perfect tandem. For a typical network, this can completely eliminate server downtime.
The benefit of this solution is that the in-memory application state of any program isn’t lost in the event of a failure and access to other applications and data is maintained. In more complex systems and networks, fault tolerance ensures that any system request will ultimately be executed regardless of failures, but it might sometimes take longer as the system adapts and reroutes requests through its redundancies.
However, since the redundant systems are operating in synch with each other, any software problem that causes one to fail will spill over into the mirrored system, making fault-tolerant computing vulnerable to operating system or application errors that could still result in server downtime or even a data center outage.
What is High Availability Architecture?
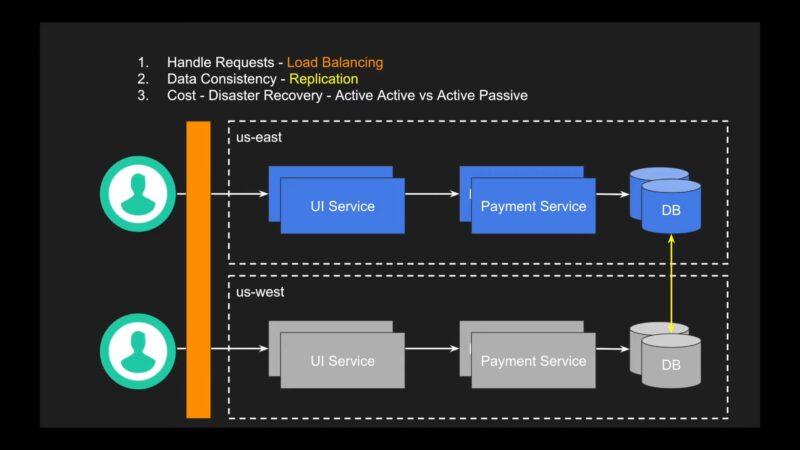
A high-availability solution is a software-based approach to minimizing server downtime. Rather than replicating redundant physical hardware, this solution clusters a set of servers together that monitor each other and have failover capabilities.
When something goes wrong on the primary server, be it a software error, application failure, or hardware fault, one of the backup servers springs into action and restarts the applications that were active on the crashed server. High availability architecture can recover from failures very quickly, but there is a server downtime lag which can result in critical data and applications being unavailable while the system reboots.
In-memory application states are often lost, although the solution is typically flexible enough to recover data that was running on another server in the cluster. Since backup servers in a high availability architecture are independent of one another, they offer substantial protection against software failures and data center outages.
If the primary server goes down due to an operating system error, the problem won’t be replicated in the independent backup server.
Fault Tolerance vs High Availability: Which One is Better?
The truth is that it depends. Fault-tolerant systems provide an excellent safeguard against equipment failure but can be extraordinarily expensive to implement because they require a fully redundant set of hardware that needs to be linked to the primary system.
High-availability architecture is much more cost-effective, but also brings with them the possibility of costly downtime, even if that downtime only lasts for a few moments. Typically, fault-tolerant systems are applied in industries or networks where server downtime is simply not acceptable.
Any system that could potentially have an impact on human lives, such as manufacturing equipment or medical devices, will usually incorporate fault-tolerant computing into its design. From a network IT standpoint, critical infrastructure may utilize fault-tolerant systems because the solution makes sense for hardware and data center redundancies.
It ensures that if someone unplugs a server, the entire system won’t go down because functions are being mirrored on a redundant server. Unfortunately, fault-tolerant computing offers little protection against software failure, which is a major cause of downtime and data center outages for most organizations.
High availability architecture makes more sense for a company that provides software-driven services, where a few moments of server downtime may hurt the bottom line but doesn’t put anyone’s lives at risk. Since high-availability architecture doesn’t require every piece of physical IT infrastructure to be replicated and integrated, it is a much more cost-effective solution.
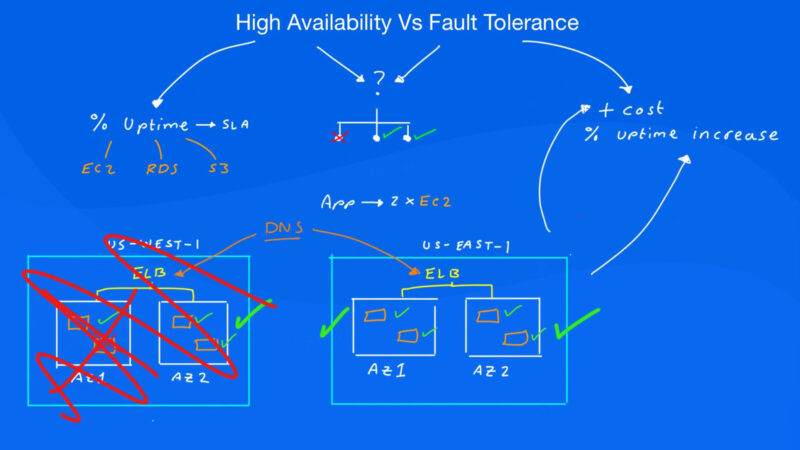
Most organizations are willing to accept the possibility of occasional downtime over the certainty of paying to implement a fault-tolerant solution that may still be compromised by software problems. Luckily, today’s data centers and service providers are getting better and better at delivering high levels of server uptime despite the increasing usage demands.
By implementing a wide range of strategies to provide backups and other redundancies, they can help customers get access to the applications and services they need with minimal disruption.
FAQ
Are fault tolerance and high availability the same thing?
No, fault tolerance and high availability are not the same. They are two different approaches to ensuring system uptime and redundancy. While they both aim to minimize downtime, they achieve this goal in different ways.
Which approach is better for critical infrastructure and industries where downtime is not acceptable?
Fault tolerance is the preferred choice for critical infrastructure and industries where any downtime can have severe consequences, such as medical devices or manufacturing equipment. It ensures that hardware failures do not lead to downtime.
Is fault tolerance more expensive to implement than high availability?
Yes, fault tolerance is generally more expensive to implement because it requires a fully redundant set of hardware that needs to be linked to the primary system. High availability architecture is a more cost-effective solution as it involves clustering servers and does not require an exact hardware replica.
What is the main difference between fault tolerance and high availability?
The main difference lies in their approach to redundancy. Fault tolerance relies on full hardware redundancy, with mirrored systems operating in lockstep to eliminate downtime in the event of hardware failures. High availability, on the other hand, uses software-based clustering to minimize downtime by quickly switching to backup servers in case of failures.
Final Words
Understanding the distinctions between fault tolerance and high availability is crucial for organizations seeking to maintain optimal uptime and data redundancy. While fault tolerance provides hardware redundancy and eliminates downtime due to hardware failures, it can be costly.
On the other hand, high availability architecture offers a more cost-effective approach, relying on software-based clustering to minimize downtime, especially in cases of software errors and server failovers. The choice between these two approaches depends on an organization’s specific needs and tolerance for downtime.







